I assume you've read The Prospero Challenge,
this is my implementation of that:
source code
(which should be fun if you enjoy reading code in unfamiliar languages).
The gist is that it evaluates a giant sdf expression and draws a pretty picture.
Mine is certainly not the fastest prospero but if you include compile time it's suddenly very competitive.
Background
I've spent a few years writing a compiler for a language that relies heavily on compile time execution
(not
a
new
idea).
When I run code at compile time, it's JIT compiled to native machine code
by the same backend used for the normal runtime part of the program.
So it's very important to me that my backend be fast because compiling any
program requires jitting many functions that will only be called a few times
and then thrown away, not even included in the final executable.
So my idea is that prospero should be a fun demo of another program that benefits
from a lightweight jit.
I've experimented with various backends for my compiler: llvm, cranelift, qbe, and just generating c.
None of them met my performance/complexity goals except the current iteration.
It started as a port of qbe to my own language.
I found qbe's code a bit inscrutable at first and I care a lot about understanding
every bit that goes into my programs, so I found the best way to bridge that gap
was to type in and translate every line of code. As a side benefit it allows my compiler to be entirely self hosted, which is neat.
Notably qbe's compilation model is: (you make a file of text ir, exec qbe on it,
which parses the text and outputs assembly as text, which you then exec a separate assembler on to get a binary).
That's impractical given my requirement to compile and call lots of individual functions throughout compilation.
So I made a few improvements to my port:
- a library interface
- my own instruction encoding for (arm64, amd64, riscv64) to jit directly into memory
- output mach-o and elf executables directly
- adhoc mach-o code signatures so i don't depend on xcode
- a web assembly target
- atomics and new bit manipulation instructions
- better arm instruction selection, a late stack slot removal pass, and speed up a various things
- more extensive tests (or at least different enough that i found bugs to fix upstream)
My version is not a sane replacement for all users of qbe but it's a much better fit for my own purposes.
Back To Prospero
starting point
I'm a big believer in starting with the simplest thing that would possibly work,
so there's always a sane place to fallback to if I end up losing morale.
In this case that's just parse the .vm file, convert it to my ir, jit a function, and call it for every pixel.
Brute force evaluation is slow but has many redeeming qualities.
Such as giving you many seconds to reflect on how it could be improved.
float ops
Looking in a profiler, the first thing that stood out to me was spending a lot of time
in the stubs for calling dynamically linked libc math functions. There are a few operations
(sqrt, fmin, fmax) that can be done with a single instruction on all the architectures
I care about but that my backend doesn't support because this is kinda my first program
with float stuff in the hot path.
Calling a libc function isn't exactly slow. You save a few registers, load a GOT entry,
jump there, do the work, jump back, load a few registers. However, when the competition
is... you increment the instruction pointer... and it has to happen millions of times
I guess it starts to add up. It's hard to compete with free.
Probably more important than the direct function call overhead
is when most of the instructions are external calls using a fixed abi, it removes most of
the register allocator's freedom and ends up with a lot of mindlessly shuffling x0 around.
I added support for sqrt/min/max as first class instructions in the backend.
So instead of all those calls, the operations can be inlined, participate in
register allocation, get more compact encoding in the ir, lot's of good stuff.
Slightly abandoning my original goal of just demoing my generic backend,
but I figure a rising tide raises all ships.
Any other programs I write that do those operations will get a tiny bit faster too.
libc: 3.782 s ± 0.024 s
sqrt: 3.445 s ± 0.008 s
fmin: 2.576 s ± 0.022 s
fmax: 1.557 s ± 0.002 s
Turns out computers really like being able to just churn through a flat stream of arithmetic.
quad tree intervals
Time to abandon brute force and try to steal
fidget's
interval arithmetic trick: split the image into a quad tree and recurse down.
The position in the tree gives bounds on the input values
which can be propogated through the ir by applying
identities from wikipedia.
If the sign of the output is known, none of the pixels in that area need to be manually evaluated.
1.034 s ± 0.002 s
I've tried to be brief on the parts of this optimization that are well covered
by other prospero write ups. It's all very cool but none of what I did is novel
and I don't have anything better to say than others have already written.
If you're interested scroll to the bottom of the original prospero challenge article and click a link.
jit more
Before I was only using intervals to discard whole regions
but any evaluation of the original expression is wasted heat.
When the intervals for min/max arguments don't overlap, one side is redundant
and the expression can be simplified even if there isn't enough information to skip the whole thing.
Jit the smaller version a few steps down the quad tree and then use that for all the children.
976.1 ms ± 14.9 ms
Not impressive! Clearly I'm doing something wrong.
Profiler reveals I've successfully reduced the time spent running the jitted expressions
but now I'm spending lots and lots of time in libsystem_platform_memmove.
While recursing down the tree, the expression is mutated but eventually the branch
ends and it needs to rewind to take a different path starting from a previous expression
since the old intervals aren't valid on the new path.
This involves lots of copying the ir data structure to save before recursing.
Each temporary value in the ir is an index into an array of kinda chunky Tmp structs
with a bunch of fields used in various different backend passes.
But the premise here is that by the time the expressions reach the backend most of the values
won't be used anymore. The large starting expression has a very large tmp array
that I copy at every level of recursion.
So I remove dead instructions with a backwards pass at each level
(rather than making the backend do it later)
and renumber the tmps so that all the live values are at low indices
to shrink the range that needs to be saved and restored.
It should also make it more cache efficient for the backend.
That also increases the number of quad tree levels and depth at which to jit I can do before it slows down.
The deeper it goes the smaller the expressions get
but the more times the simplifications/backend are invoked.
I should probably have a program that scans all the combinations
but for now it's easier to just find the inflection point by manually trying a few.
718.8 ms ± 1.3 ms
Actually, the simplifications only mutates instructions.
The arrays of temporaries and constants don't need to be copied at all
until the level where they're handed off to the backend.
661.6 ms ± 0.8 ms
mul sign
disclaimer
None of the timings in this section are very scientific across commits.
I've worked on this very sporadically so there have been other compiler changes in between.
There were 6 months between prospero commits here and it got slower!
The notable backend change was global value numbering which is a runtime vs comptime speed tradeoff.
Or maybe i just changed how i was measuring (notably the time format in my notes changed).
The important thing is that i wrote the starting time too
so i know the individual change here was a clear improvement and that the general trend is positive.
Similarly the commits linked here are mixed in with other changes.
This is less of a polished standalone project and more of a fun stress test for my compiler.
804ms
I'd missed an important interval rule: x squared can't be negative.
Also started using a bit set for tracking which temporaries have a known interval/copy value
instead of memset-ing to clear the map every time.
245ms
tighter logic
230ms
A touch of mechanical sympathy yields slightly more speed.
Cache locality is good so renumbering tracks indices with a packed array instead of a field on the tmp struct.
Branches are bad so tried to simplify a special case for O.copy in the interval opt code.
190ms
The inflection point for jit depth moved again.
170ms
Something I find fascinating here is that the performance gain from
just not doing pessimizing things in the surrounding code just as important
as the clever interval arithmetic stuff. It's so easy to cancel out an algorithmic improvement
with a dumb mistake.
Interpreter
My backend isn't specifically tuned for this program.
It's still running a several of optimization passes that are useful
for real programs but a waste of time for flat math traces like this.
In fact, at this point it's slightly faster to just interpret the ir after doing the interval
simplification instead of compiling it. but it's cool that their speeds are fairly similar.
Comparison
To see where I stand so far, I timed a few of the other submissions on my machine so the numbers can be compared.
lukegrahamlandry/franca examples/prospero.fr cf0d2427af2d6b5b46789350d9998889035cbc3a
build aot -unsafe; 0.71s user 0.06s system 134% cpu 0.572 total
run; Time (mean ± σ): 163.9 ms ± 7.7 ms [User: 141.1 ms, System: 12.5 ms]
jit (inherit backend); Time (mean ± σ): 536.7 ms ± 6.6 ms [User: 586.9 ms, System: 41.3 ms]
build aot -unsafe !FEAT_JIT; 0.25s user 0.03s system 108% cpu 0.254 total
run; Time (mean ± σ): 129.8 ms ± 8.6 ms [User: 106.9 ms, System: 12.1 ms]
jit; Time (mean ± σ): 390.6 ms ± 8.0 ms [User: 378.3 ms, System: 27.9 ms]
own loc: 558. backend: 24k.
apribadi/prospero-challenge-renderer NUM_RESOLUTIONS=1 (1024) NUM_ITERATIONS=0 WARMUP=false 70ba8136d33dfe97c7e124936412aabab1d8d378
make; 0.30s user 0.07s system 94% cpu 0.396 total
run; Time (mean ± σ): 3.4 ms ± 1.5 ms [User: 2.7 ms, System: 2.2 ms]
own loc: 1224.
(note: run doesn't include optimising the expression but make does so still faster than everyone else if you include both)
Janos95/prospero_vm num_runs=1 f4f83b05be3fc21e1c66e46c802241cc37aacdb3
make; 0.60s user 0.08s system 101% cpu 0.672 total
run; Time (mean ± σ): 37.5 ms ± 3.3 ms [User: 57.9 ms, System: 15.0 ms]
own loc: 510.
simeonveldstra/prospero-c f7adbeaea00ae4b02de159f322e294fcee15ae4c
make; 0.20s user 0.05s system 109% cpu 0.229 total
run; Time (mean ± σ): 962.9 ms ± 33.7 ms [User: 6691.1 ms, System: 25.2 ms]
own loc: 595.
~coyotes/prospero 8431ec08705641aca0a2a1483456c61895154c24
build; 2.94s user 0.60s system 174% cpu 2.030 total
run; Time (mean ± σ): 6.773 s ± 0.416 s [User: 50.736 s, System: 0.168 s]
build --release; 5.01s user 0.58s system 229% cpu 2.439 total
run; Time (mean ± σ): 1.433 s ± 0.043 s [User: 10.957 s, System: 0.033 s]
own loc: 418. Cargo.lock: 76 lines.
a-viv-a/prospero-jit-rs 12b4ae70384299297a32a9ad9361df64b2bd0d2c
build; 33.28s user 2.98s system 314% cpu 11.512 total
run; Time (mean ± σ): 864.4 ms ± 4.9 ms [User: 2116.5 ms, System: 28.5 ms]
build --release; 76.74s user 3.45s system 412% cpu 19.446 total
run; Time (mean ± σ): 108.4 ms ± 2.2 ms [User: 412.0 ms, System: 18.2 ms]
own loc: 143. Cargo.lock: 562 lines. cranelift: 200k.
mkeeter/fidget -pfidget-cli (render2d -i models/prospero.vm -s 1024) f6452274efaea15aad859294e5d617737c67a016
build; 139.55s user 12.09s system 555% cpu 27.314 total
run --eval=vm; Time (mean ± σ): 880.9 ms ± 5.2 ms [User: 2522.2 ms, System: 11.7 ms]
run --eval=jit; Time (mean ± σ): 857.7 ms ± 9.6 ms [User: 2297.9 ms, System: 12.7 ms]
build --release; 425.74s user 15.67s system 617% cpu 1:11.50 total
run --eval=vm; Time (mean ± σ): 28.1 ms ± 0.7 ms [User: 76.0 ms, System: 4.9 ms]
run --eval=jit; Time (mean ± σ): 26.4 ms ± 0.7 ms [User: 59.9 ms, System: 6.3 ms]
own loc: 19478. Cargo.lock: 5572 lines.
morazow/prospero-rust (--size=1024) 451b981aa68df9a11d4931bbf6028358caf5f97b
build; 29.32s user 5.20s system 216% cpu 15.971 total
run --backend=llvm; Time (mean ± σ): 2.031 s ± 0.009 s [User: 2.018 s, System: 0.011 s]
run --backend=asmjit; Time (mean ± σ): 792.7 ms ± 6.4 ms [User: 785.2 ms, System: 5.0 ms]
build --release; 42.47s user 5.37s system 272% cpu 17.551 total
run --backend=llvm; Time (mean ± σ): 1.788 s ± 0.007 s [User: 1.775 s, System: 0.010 s]
run --backend=asmjit; Time (mean ± σ): 749.2 ms ± 4.0 ms [User: 742.8 ms, System: 4.6 ms]
own loc: 1317. Cargo.lock: 311 lines. llvm: 2000k.
+∞ build time for using precompiled llvm
cfbolz/pyfidget c 9e039e379470ed50003cf588a0460aa359948b55 (musttail didn't compile)
make; 0.19s user 0.04s system 114% cpu 0.203 total
run; Time (mean ± σ): 1.739 s ± 0.005 s [User: 1.730 s, System: 0.008 s]
+∞ output image was upside down
notes
all numbers on a 2020 m1 macbook air.
i ran cargo build once before taking measurements and cargo clean between everything.
so build times include compiling dependencies but not downloading them.
i ran the output binary directly (not with cargo run) with hyperfine --warmup=1
tools:
- rustc 1.93.0-nightly (20383c9f1 2025-11-03)
- Apple clang version 17.0.0 (clang-1700.3.19.1)
- cloc 2.02
things i skipped:
- ones that sounded like they only support amd64 or nvidia gpus.
- c++ that did not successfully compile by typing `make`
- can't be bothered to install julia or rpython. tho todo: maybe they're fast because less compiler.
notes:
- c and rust precompile their standard libraries. franca doesn't.
- for franca,
aot means franca examples/default_driver.fr build examples/prospero.fr -o q.out -unsafe and
jit means FRANCA_NO_CACHE=1 franca examples/prospero.fr
threads
In the comparison section above, you might notice that most entries have a much higher
User value than Time value. That just means they're using multiple threads.
I think it's boring to make it faster by throwing more cores at it,
but I also think it's cringe that my number is lower than other people's number.
On the first level of quad tree, spawn a thread to do that section.
build aot -unsafe; 0.71s user 0.06s system 134% cpu 0.578 total
run; Time (mean ± σ): 79.7 ms ± 4.7 ms [User: 165.7 ms, System: 15.4 ms]
Note that I didn't get the expected 4x speedup from having 4 threads.
Profiler reveals I'm now spending 40ms perfectly parallel to build up the bit set
of which pixels are set in the final image. Then the threads join and I spend another
40ms iterating the bit set and printing out a (P3 plain) ppm image. In the beginning the
rendering was so slow that this part at the end didn't matter but now it's eating into my time!
printing the numbers a bit more efficiently:
FEAT_JIT; Time (mean ± σ): 61.4 ms ± 7.5 ms [User: 147.3 ms, System: 15.8 ms]
!FEAT_JIT; Time (mean ± σ): 49.7 ms ± 5.9 ms [User: 106.9 ms, System: 13.3 ms]
disclaimer
see "fearless concurrency" section belowemit_c
Thus far my program has itself been compiled by my own backend,
while other people's programs have been compiled by rustc/clang using llvm's optimizations.
If you care more about runtime speed than compile speed, llvm is a great choice.
luckily i can get in on that action too. i have a program that converts post-sema franca asts
to c code, it's incomplete but it works well enough to compile the prospero program.
then that c code can be compiled by clang -O2 and benifit from more optimizations.
the prospero.vm sdf program still uses my backend, it's just that the backend code itself
optimizer/codegen/etc will take a detour through c.
FEAT_JIT
emit_c; 0.50s user 0.04s system 99% cpu 0.544 total
clang -O2; 6.33s user 0.09s system 100% cpu 6.394 total
run; Time (mean ± σ): 43.6 ms ± 4.8 ms [User: 93.1 ms, System: 16.2 ms]
clang -O0; 0.57s user 0.06s system 84% cpu 0.738 total
run; Time (mean ± σ): 426.2 ms ± 5.2 ms [User: 1238.5 ms, System: 19.0 ms]
!FEAT_JIT
emit_c; 0.22s user 0.02s system 99% cpu 0.239 total
clang -O2; 0.68s user 0.04s system 102% cpu 0.703 total
run; Time (mean ± σ): 32.7 ms ± 2.0 ms [User: 59.1 ms, System: 14.3 ms]
clang -O0; 0.19s user 0.02s system 116% cpu 0.185 total
run; Time (mean ± σ): 347.6 ms ± 4.6 ms [User: 956.2 ms, System: 16.6 ms]
So -O2 gives a ~30% runtime improvement over my compiler
at the cost of a 3x-12x longer compile time, not bad if you're into that sort of thing.
Also -O0 is completely unserious. Imagine how embarrassing it would be to buy a c compiler slower than that.
png
I feel a bit like mine is cheating by outputting the trivial .ppm format instead of .png like fidget does.
My area of interest is not png encoding so at this point I'd like to just use someone else's library.
One small problem, nobody has written a png library in my language.
I follow the standard extern-c abi so I could just compile a c library with clang and link against it,
but that's kinda boring, then I depend on a whole c toolchain and cross compiling gets a bit annoying.
Instead I have
my own c frontend
that outputs the binary format of my ir, including signature information so I don't have to manually write bindings.
It's similar to the importC feature in D or Zig except it's just
normal code that runs at compile time instead of a feature builtin to the compiler.
The end result is there's
very little boilerplate required for me to include
stb_image_write.h in my program.
FEAT_PNG FRANCA_NO_CACHE=1
build aot -unsafe; 1.14s user 0.08s system 121% cpu 1.002 total
run; Time (mean ± σ): 78.9 ms ± 5.0 ms [User: 170.4 ms, System: 12.9 ms]
build aot -unsafe !FEAT_JIT; 0.66s user 0.05s system 106% cpu 0.667 total
run; Time (mean ± σ): 65.8 ms ± 3.9 ms [User: 122.3 ms, System: 10.6 ms]
These build times include jit compiling my c compiler from source to run at comptime,
using it to compile stb_image_write, and then finally compiling my prospero.
If I build without FRANCA_NO_CACHE=1, the compiled ir for the c library gets reused,
import_c doesn't have to be recompiled, and build times drop back down about to what they were before.
FEAT_PNG
FEAT_JIT; 0.71s user 0.06s system 135% cpu 0.568 total
!FEAT_JIT; 0.25s user 0.02s system 113% cpu 0.247 total
wasm
It also supports web assembly, with a high speed penalty.
However magical you might hope v8 is, wasm isn't designed for being a good host for jit compilers.
To jit native code you put the code in memory and then jump there (perhaps with a bit of ic ivau
__clear_cache ceremony depending on the cpu). To jit on wasm, you produce a new web assembly module,
copy that out of linear memory into a js array buffer so you can pass it to the browser,
it then validates it, compiles it to native code, and finally puts the code in memory
and lets you jump there.
There might even be multiple levels of tiering or a baseline interpreter depending on the phase of the moon.
However, in the general case where you want to have jitted functions
callable by any thread, you also have to save every new wasm module you ever create and
at some point before trying to use them have other threads synchronize and replay
instantiating all those modules so they have an equivalent table of function pointers.
open demo
There's lots room for improvement here.
It seems that it doesn't work at all in safari, FEAT_PNG doesn't work in firefox,
both work in chrome but not if you have the console open while it runs??
The wasm blob I have there is very large (~8MB, 2.4 gzipped).
It contains my compiler compiled to wasm and the source of all my various example programs.
The prospero program is jitted to wasm in the browser so these times are build+run.
If you edit the source to set FEAT_PNG to true and press the run button on the left,
it will print the output as a data url you can paste into your browser to view.
FEAT_JIT !FEAT_PNG; 1846ms
FEAT_JIT FEAT_PNG; 3141ms
!FEAT_JIT !FEAT_PNG; 697ms
!FEAT_JIT FEAT_PNG; 1702ms
Chrome
Version 144.0.7559.133 (Official Build) (arm64)
Finishing Touches
Simplified the interpreter dispatch a bit.
Now that I think about it, idk why I was ever doing the plain ppm (P3), the binary one (P5) should be faster to emit.
FEAT_JIT; Time (mean ± σ): 43.6 ms ± 1.9 ms [User: 132.5 ms, System: 12.6 ms]
!FEAT_JIT; Time (mean ± σ): 31.1 ms ± 1.6 ms [User: 86.6 ms, System: 10.9 ms]
One more with !FEAT_JIT emit_c clang -O2 so i can declare my best run time:
Time (mean ± σ): 22.2 ms ± 2.8 ms [User: 50.2 ms, System: 11.2 ms]
(Just to be totally fair, that one was taken with -i path/to/prospero.vm
so I'm reading/parsing the file at runtime like everyone else instead of doing it at comptime.
It's less than a 2ms difference tho, which is boring because it's within the error bars).
Some Conclusions
Contrary to appearances, I don't think it's super important what language something is written in.
I'm aware that nothing good about my program was exclusively possible because it was done in my language.
On the flip side, it's interesting that using my own language also wasn't an impediment.
My results weren't at bottom of the leaderboard. If you looked only at the runtime performance numbers
it wouldn't be obvious which were (optimized by millions of lines of llvm) and which
were (compiled by a toy typed in to one computer by one person over a couple years). If the problem being
solved is a very discrete computation, the ceiling on the impact of your tooling is surprisingly low.
What I do think is important is how much of your program you understand.
Forcing myself to use an unreasonable amount of my own stuff
is a good way to be familiar with an unreasonable amount of the stuff I use.
There is great freedom in all our bugs are belong to us.
if you want to try it natively
git clone https://git.sr.ht/~lukegrahamlandry/franca && cd franca && ./boot/strap.sh -no-test && ./target/franca.out examples/prospero.fr > a.ppm
That downloads an old compiler and the latest source, bootstraps a new compiler, and uses it to jit my prospero.
Should work on macos/linux arm64/amd64. I also support linux riscv64 but I don't distribute a binary so the bootstrap requires cross compiling.
The whole thing takes ~20 seconds on my machine (which includes the download and my compiler compiling itself 8 times).
Outputs a 1024x1024 prospero in a.ppm (sha256:eaf99bcf6ab0ee750678cbef374e5fcbc7548d2385b4718c6d1e0e04ae0cc656).
Correctness
Not all the prosperos I compared have the same output.
The images below are made with diffchecker.com's image subtraction tool.
Comparing fidget (which I assume is correct) with different answers.
Something to note is that my png and ppm are very slightly different so there is perhaps something
strange going on with how the tool compares different formats?
png and ppm are both lossless and I can't explain why they'd end up with
different pixels so take these results with a large grain of salt.
(collapsed comparison images)
mine png:

mine ppm:

a-viv-a:

coyotes:
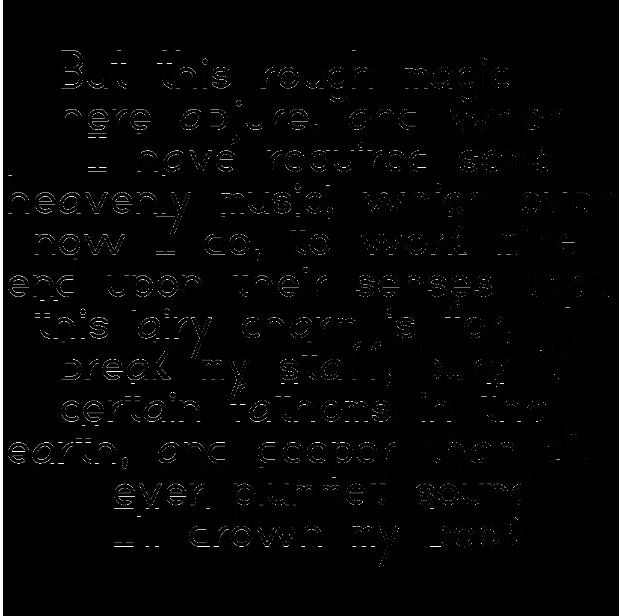
simeonveldstra:
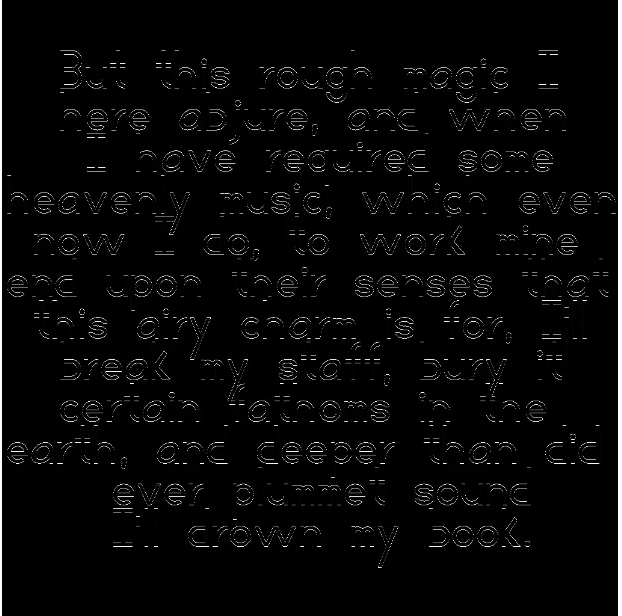
morazow:
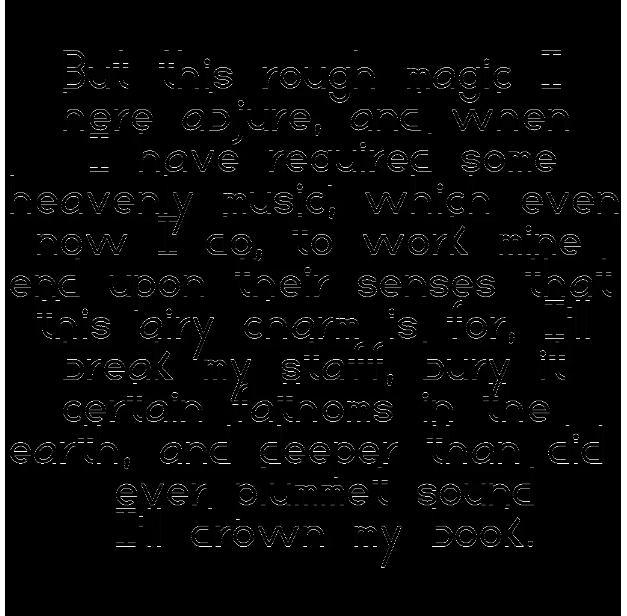
janos95:

fearless concurrency
I made a dumb mistake! I was updating one bit set on multiple threads.
I store the bits in i64 chunks so they don't have unique addresses and I don't update them atomically.
So if one i64 chunk is split on the boarder between threads,
they can stomp on each other and lose bits
(if you run it at resolutions where a quad-tree-boundary is split across a bit chunk).
Trivial to fix by giving each thread its own set and merging them at the end
but embarrassing that it took a month of my tests being flaky to decide it was worth fixing.
(I had a test at 64x64 resolution becuase it was written before i made 1024x1024 run at a tolerable speed).
Luckily for my writeup, that doesn't change the speed/output discussed above.
Unfortunately for my world view, that mistake would have been caught if my langauge had blazingly safe Sync and Send traits.
Once they figure out how to do that, without also forcing the compiler to deliver the executable via snail mail, it will all be over for me :)
next: Shapes and Colours Considered Insecure
change log
[Feb 18, 2026] writeup
[Mar 5, 2026] add apribadi's to comparison
[Mar 14, 2026] note threading mistake